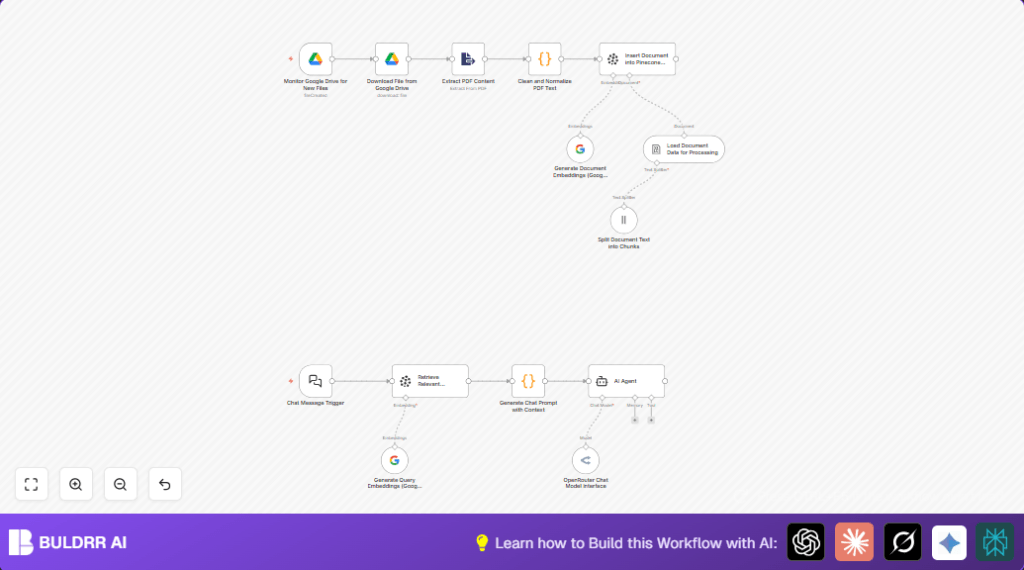
What This Workflow Does
This workflow watches a Google Drive folder for new PDF files.
It downloads each PDF, then extracts and cleans the text.
Next, it creates embeddings from the clean text using the Google Gemini model.
It adds these embeddings and document data to a Pinecone vector store for quick searches.
When a user sends a question, the workflow finds relevant documents from Pinecone and uses AI chat powered by Google Gemini to answer.
This saves many hours by automating slow manual work and speed ups document search with AI.
Who Should Use This Workflow
This workflow is for anyone who gets many PDF files to manage on Google Drive.
It helps teams that spend hours downloading, reading, and searching PDFs manually.
Especially useful for legal, research, or admin staff needing fast text search across documents.
It works great for small or large volumes needing AI chat to answer question from PDFs.
Tools and Services Used
- Google Drive Trigger node: Watches a folder for new PDFs.
- Google Drive node: Downloads files by file ID.
- Extract From File node: Extracts text from PDF binary data.
- Code node: Cleans text by removing line breaks and special characters.
- Generate Document Embeddings (Google Gemini) node: Creates text embeddings for search.
- Insert Document into Pinecone Vector Store node: Adds vectors and metadata for similarity search.
- Chat Message Trigger node: Webhook for user chat queries.
- Generate Query Embeddings (Google Gemini) node: Turns chat questions into embeddings.
- Retrieve Relevant Documents from Pinecone node: Finds documents matching the question.
- Code node (prompt builder): Combines top documents with user query to build AI prompt.
- OpenRouter Chat Model Interface node: Runs Google Gemini chat model to answer questions.
Inputs, Process, and Outputs
Inputs
- New PDF files uploaded to a specific monitored Google Drive folder.
- User questions sent to the chat webhook.
Processing Steps
- Trigger detects new PDF files on Google Drive.
- Downloads file binary data.
- Extracts raw text from PDFs.
- Cleans text by removing line breaks and special symbols.
- Generates vector embeddings of cleaned text using Google Gemini text-embedding-004.
- Inserts embeddings and document metadata into Pinecone index.
- When a question arrives, generates query embeddings from user input.
- Searches Pinecone for documents closest to user query vectors.
- Builds a prompt mixing top document snippets with question.
- Sends prompt to Google Gemini chat model for an answer.
Outputs
- Fast AI-generated answers to user questions based on PDF content.
- Stored indexed document vectors for repeated fast similarity searches.
Beginner Step-by-Step: How To Use This Workflow in n8n
Importing and Setup
- Download the workflow file using the Download button on this page.
- Open n8n editor and choose Import from File to upload the workflow file.
- After import, add Google Drive OAuth credentials to nodes that need it.
- Configure Pinecone credentials and make sure the index name matches
n8n-rag-demoor update as needed. - Enter Google Gemini API keys for embedding and chat model nodes.
- For the Google Drive Trigger node, update the folder ID if monitoring a different folder.
Testing and Activation
- Upload a test PDF to the monitored Google Drive folder and verify the workflow triggers.
- Send a test chat query to the webhook URL provided by the Chat Message Trigger node.
- Check if the workflow extracts text, creates embeddings, stores data, and returns a relevant AI answer.
- Fix any errors by checking credentials and configuration, then retest.
- Activate the workflow for production use by toggling it active.
For stable operation, if self hosting n8n, keep the n8n service running or use self-host n8n.
Common Edge Cases and Failures
- No trigger on new files: Usually folder ID is wrong or Google Drive permissions missing.
- Empty text extraction: Happens if PDFs are scanned images, which need OCR support (not included).
- Embedding or Pinecone errors: Often caused by invalid API keys or index names.
- Slow or missing chat answers: Check connection to Google Gemini chat service and webhook setup.
Customization Ideas
- Change monitored Google Drive folder ID to track other folders.
- Adjust text cleaning code to keep more or fewer characters depending on document style.
- Change embedding model names to other Google Gemini or supported models.
- Include more document snippets in chat prompts by editing prompt builder code node.
- Add notification nodes (email, Slack) after Pinecone insertion to alert when new files are processed.
Summary of Results
✓ Automated monitoring and ingestion of PDFs from Google Drive.
✓ Clean, searchable document text extracted and normalized.
✓ Fast embeddings stored in Pinecone for efficient similarity searches.
✓ AI chat answers user queries using most relevant document context.
→ Saves hours of manual file handling and text searching.
→ Speeds up legal or document-based decision workflows.
