What This Automation Does
This workflow runs automatically at set times to grab website data. It uses a special web scraping API which stops blocking from sites that fight scrapers. The workflow sends the website address to the API and gets fresh content back each time. This saves time and avoids errors from manual site checks.
The output gives new website info ready to use or save. It is made for easy changing of URLs so users can quickly swap from test to real targets. The main goal is to get up-to-date web data regularly without manual work and without getting stopped by anti-bot defenses.
Inputs, Process, and Outputs
Inputs
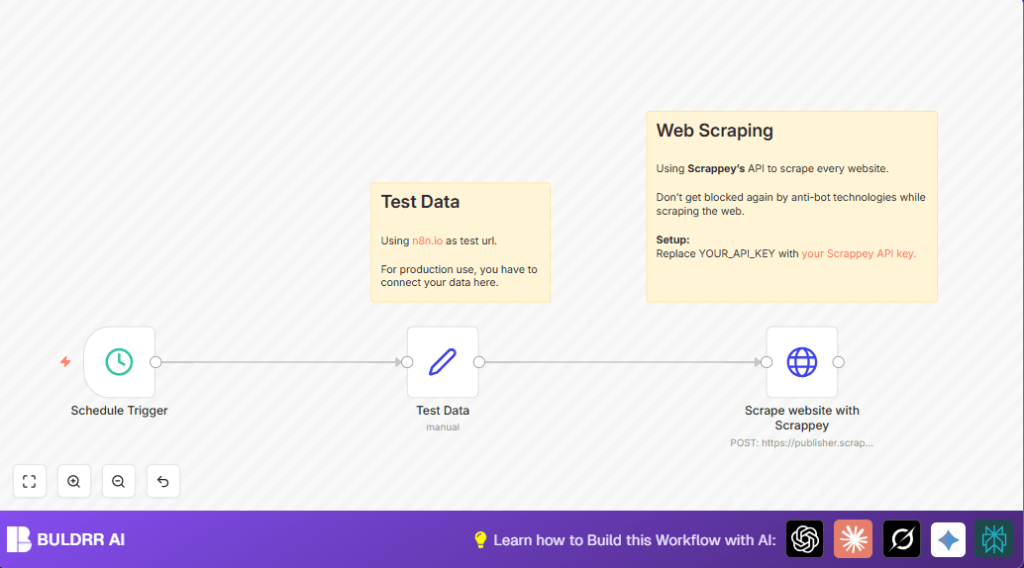
- Website name and URL, set in a node to tell the workflow what to check.
- API Key from the web scraping service, used to allow access and avoid request blocks.
- Scheduled trigger to start the workflow at selected times.
Processing Steps
- The schedule node starts the process at chosen intervals.
- The Set node enters the website details for the API call.
- HTTP Request node sends a POST to the scraping API with the site URL and the API key.
- The scraping API uses special methods to bypass bot defenses and gets website content.
- The workflow returns the scraped data for use.
Output
Fresh, scraped content from the target website that can be stored or processed next.
Who Should Use This Workflow
People who need to check websites often for price changes or new products. Especially useful for those blocked by anti-bot rules when scraping. Good for digital marketers, analysts, or anyone needing regular updated web data without spending hours clicking.
The workflow avoids problems from blocked requests and makes scraping hands-free. It works well for basic to mid-level users who want to automate web data collection in n8n.
Tools and Services Used
- n8n Automation Tool: Runs and schedules the workflow steps.
- Scrappey API: Special web scraping service that bypasses anti-bot blocks and returns site data.
- HTTP Request Node: Sends POST calls to Scrappey with required data.
Beginner Step-by-Step: How to Use This Workflow in n8n Production
Step 1: Import the Workflow
- Download the workflow file from this page using the Download button.
- Open the n8n editor where you work on automations.
- Use the “Import from File” option to bring the workflow into n8n.
Step 2: Configure Credentials
- Add your Scrappey API key in the HTTP Request node’s query parameters, replacing the placeholder
YOUR_API_KEY. - If needed, update other IDs, emails, or channels the workflow uses for further processing or notifications.
Step 3: Update Target URLs
- Go to the Set node and change the example website name and URL to actual sites you want to scrape.
- Make sure URLs are formatted correctly including https:// prefix.
Step 4: Test the Workflow
- Run the workflow once manually in n8n to check if data returns successfully.
- Review the output of the HTTP Request node to confirm it shows scraped content.
Step 5: Activate for Production
- Toggle the workflow to “Active” in n8n to enable scheduled runs.
- Check the Executions panel in n8n to monitor runs and results.
This process gets the workflow running so scraping happens automatically and regularly. No need to rebuild or tweak the nodes unless making changes.
For users running self-host n8n, import and configuration is the same.
Customization Ideas
- Change scrape frequency in the Schedule Trigger for daily, hourly, or other times.
- Use a spreadsheet or database as input instead of a single Set node to scrape many sites.
- Store scraped data to Google Sheets, databases, or cloud files with extra nodes.
- Add error handling to retry failed scrapes or send alerts when scraping fails.
Troubleshooting Common Errors
403 Forbidden HTTP Error
Problem: Scrappey API key missing or incorrect.
Fix: Check the HTTP Request node query parameters have the correct API Key. Test key on Scrappey’s site.
No Data Returned from HTTP Request Node
Problem: URL invalid or unreachable.
Fix: Confirm URL in the Set node is correct and site can be scraped by Scrappey. Try test URL like https://n8n.io/.
Pre-Production Checklist
- Make sure the Scrappey API key is valid and has enough quota to use.
- Test the workflow using the example URL to verify output.
- Set schedule interval carefully to avoid scraping too often.
- Keep API keys private and secure to avoid leaks.
- Backup the workflow file before full production use.
Deployment Guide
Turn the workflow active in the n8n editor once fully tested.
Watch progress in the Executions panel to confirm regular successful scraping.
Set alerts using n8n’s Error Trigger node or external tools for failures.
Be aware of Scrappey API rate limits to prevent service stoppage.
Conclusion
This workflow removes manual website checks and battle with anti-bot pages.
Users get automatic fresh web data on schedule, without errors or hassle.
Next steps can include multiple sites, data storage, and more detailed parsing.
Good for saving time and getting reliable info fast.
Summary
→ Workflow automates timed web scraping using Scrappey API.
→ Stops blocking by anti-bot tech on target websites.
✓ Produces updated website content automatically.
✓ Easy to change URLs from test to real targets.
✓ Saves hours and prevents scraping errors.
