What This Automation Does ⚙️
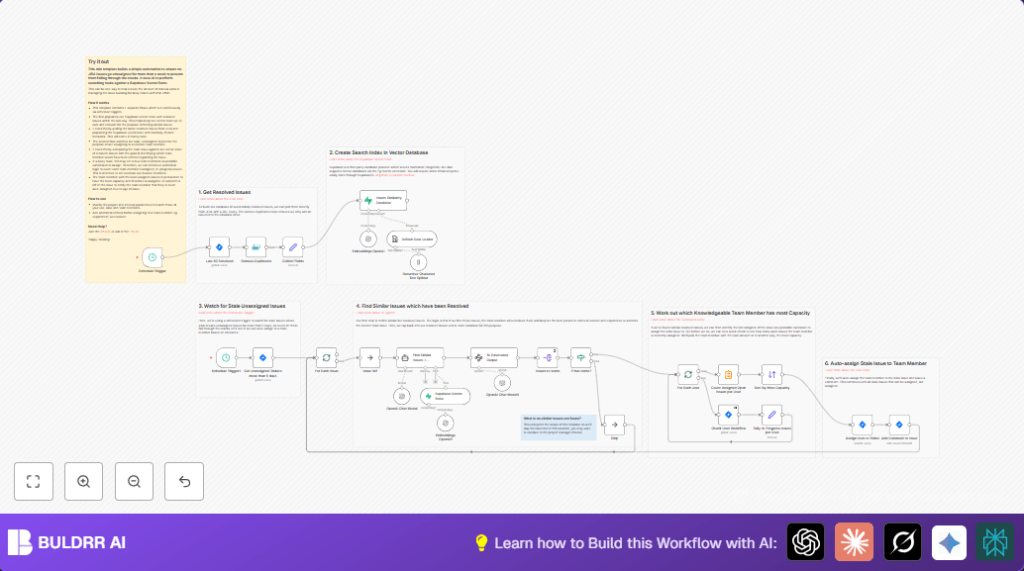
This n8n workflow finds old JIRA issues not assigned to anyone for more than 5 days.
It looks into past solved issues and finds who worked on similar problems.
Then, it checks how busy each possible team member is now.
The workflow assigns the old issue to someone with the right experience and the most free time.
This saves time and stops important problems from waiting too long without action.
Tools and Services Used
- Jira Software Cloud API: Access and manage JIRA issues.
- Supabase with Pg-Vector: A database that stores and searches issue embeddings.
- OpenAI API: Creates text embeddings and runs AI chat models.
- n8n Automation Platform: Orchestrates the workflow steps.
Beginner Step-by-Step: How to Use This Workflow in n8n
1. Import Workflow
- Download the workflow file using the Download button on this page.
- Open your n8n editor.
- Use Import from File to load the downloaded workflow.
2. Configure Credentials
- Add your API Keys and credentials for Jira, OpenAI, and Supabase inside n8n.
- Update any project keys, user IDs, or table names if needed to match your environment.
3. Test the Workflow
- Run the workflow manually to check if it fetches and processes issues correctly.
- Look at the debug data to confirm correctness.
4. Activate for Production
- Enable the schedule trigger nodes to make the workflow run automatically.
- Monitor the execution logs in n8n for errors or issues.
- Consider using self-host n8n for stability if running on your own server.
Workflow Inputs, Processing, and Outputs
Inputs
- JIRA issues that are marked “Done” and assigned within the last day.
- JIRA issues in “To Do” status unassigned for over 5 days.
- User workload data from open “In Progress” issues.
Processing Steps
- Retrieve resolved issues and remove duplicates.
- Extract key details like issue keys, descriptions, assignees.
- Create text data from issues, generate embeddings using OpenAI.
- Insert embeddings and metadata into Supabase vector database.
- Regularly query for old, unassigned tickets.
- Find similar past issues and candidate assignees using Langchain AI agents.
- Check each assignee’s current workload in JIRA.
- Sort assignees by available capacity.
- Assign the issue to the best candidate and add an explanatory comment.
Outputs
- Old JIRA issues get auto-assigned to the best team member.
- Comments are added to issues explaining the automated action.
Edge Cases and Failures
- If no similar past issues are found for an old ticket, assignment is skipped or escalated.
- API rate limits from OpenAI may slow the workflow; consider throttling.
- Incorrect JQL queries can cause data retrieval failures.
- Supabase insertion errors usually come from wrong database setup or missing Pg-Vector extension.
- Assignments can fail if user IDs or sorting is misconfigured.
Customization Ideas
- Change JQL queries to handle multiple projects or specific issue types.
- Select different AI models for faster or cheaper embedding generation.
- Add escalation paths to notify managers when no match is found.
- Set maximum allowed workload thresholds before assigning new issues.
Summary of Benefits
✓ Saves hours of manual issue review every week.
✓ Stops critical issues from being forgotten or delayed.
✓ Automatically assigns old tickets to the most suitable team members.
→ Keeps projects moving by reducing backlog build-up.
→ Ensures team workload is balanced based on real-time data.
Step 4 Example: Extracted Fields in Set Node
You can use expressions to get issue data. For example:
{
"project_key": "{{$json.fields.project.key}}",
"issue_key": "{{$json.key}}",
"issue_type": "{{$json.fields.issuetype.name}}",
"created_date": "{{$json.fields.created}}",
"resolved_at": "{{$json.fields.resolutiondate}}",
"assignee_id": "{{$json.fields.assignee.accountId}}",
"assignee_name": "{{$json.fields.assignee.displayName}}",
"title": "{{$json.fields.summary}}",
"description": "{{$json.fields.description}}"
}
This setup keeps your data clean and consistent for the vector database.
Step 5 Prompt Example in Default Data Loader Node
The node formats issue text like this before embeddings:
jsonData: # {{$json.title}}
- created {{$json.created_date}}
- resolved {{$json.resolved_at}}
## description
{{$json.description}}
Use this clear format so the AI understands the context well.
Step 16 Example: Auto-assignment Comment
Add comments on assigned issues to keep things clear:
Auto-assigned to {{assignee_name}} due to no assignee within past 5 days.
This transparency helps the team know why assignments happened.
