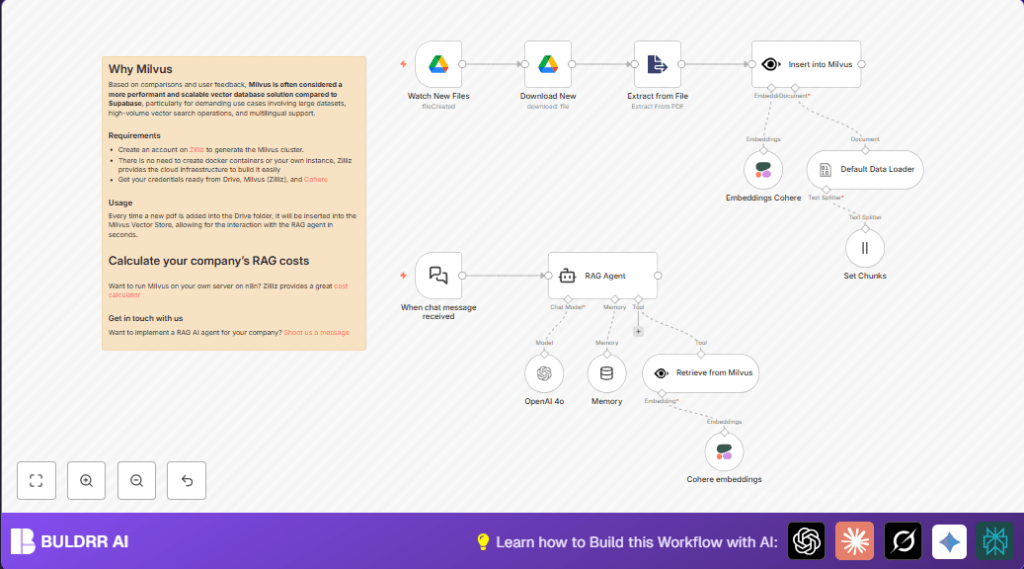
What this workflow does
This workflow watches a Google Drive folder for new PDF files and processes them automatically.
It extracts text from the PDFs, splits the text into small chunks, and creates embeddings of those chunks with Cohere.
Then it stores those embeddings in Milvus, a vector database, for fast search.
Finally, a chat agent uses the stored data to answer questions by finding the most relevant document pieces and generating clear responses with OpenAI GPT-4o.
Who should use this workflow
This workflow is helpful for anyone who needs to quickly find answers inside many PDF documents.
It helps teams save time by automating the boring, slow process of reading and searching PDFs.
No deep technical skills are needed to use it if basic knowledge of n8n is present.
Tools and services used
- Google Drive: To store and monitor PDF files.
- Extract from File node in n8n: To get text from PDFs.
- Cohere Embeddings API: To create vector embeddings from text.
- Milvus: To save and search vector embeddings fast.
- OpenAI GPT-4o Chat: To generate AI answers.
- n8n: To automate the whole pipeline.
Inputs, processing steps, and output
Inputs
- New PDF files arriving in a specific Google Drive folder.
Processing Steps
- Detect new files with the Watch New Files Google Drive node.
- Download PDFs using Download New Google Drive node.
- Extract text with the Extract from File node.
- Structure text using the Default Data Loader node.
- Split texts into chunks with the Text Splitter: Recursive Character Text Splitter node.
- Create embeddings of chunks via the Embeddings Cohere node using model “embed-multilingual-v3.0”.
- Store embeddings in Milvus with the Insert into Milvus node.
- Wait for chat input with the When Chat Message Received node.
- Retrieve best documents from Milvus with Retrieve from Milvus inside the RAG Agent node.
- Use Memory Buffer Window to keep chat context.
- Generate AI answers with OpenAI GPT-4o Chat node.
Output
Fast, relevant AI answers based on the PDF documents stored in the vector database.
Beginner step-by-step: How to use this workflow in production
Step 1: Download the workflow file
- Find the Download button on this page.
- Click it to save the workflow file (.json) to your computer.
Step 2: Import workflow into n8n
- Open the n8n editor where your account is ready.
- Click on the menu, choose “Import from File.”
- Select the downloaded workflow file to load it.
Step 3: Configure API Keys and IDs
- Enter Google Drive credentials so the workflow can access your files.
- Put your Cohere API Key in the Embeddings Cohere node settings.
- Add Milvus API credentials and confirm the collection name in the Insert into Milvus node.
- Add your OpenAI API Key in the OpenAI GPT-4o Chat node.
- Update folder ID in the Watch New Files node to your Google Drive folder.
Step 4: Test the workflow
- Add a sample PDF to your chosen Google Drive folder.
- Run the workflow manually or wait for the trigger to activate.
- Check if the text is extracted, embedded, and stored in Milvus.
- Send a test chat message to see if the AI returns relevant answers.
Step 5: Activate workflow for production
- Turn the workflow status to active in n8n.
- Make sure n8n is running continuously (or see self-host n8n if needed).
- The workflow will watch your folder, process new PDFs, and answer questions automatically.
Customization ideas
- Change the Cohere embedding model to match your language or data needs.
- Adjust chunk size and overlap in the Text Splitter node to balance speed and context.
- Replace Milvus with other vector databases like Supabase or Pinecone by switching their nodes and credentials.
- Increase conversation memory size in the Memory Buffer Window node for longer chats.
- Monitor different Google Drive folders by changing the folder ID in the Watch New Files node.
Common problems and solutions
- Problem: No new files detected by the Watch New Files node.
Cause: The folder ID might be wrong or permission issues exist.
Solution: Check the folder ID carefully and verify Google Drive API access rights. - Problem: PDF extraction returns empty or error in Extract from File.
Cause: The PDF could be encrypted or damaged.
Solution: Try with a standard PDF or convert the PDF and test again. - Problem: Milvus insertion fails or times out.
Cause: Wrong API credentials or collection info.
Solution: Verify Milvus credential settings and check collection name, plus Zilliz cloud status if hosted.
Pre-Production checklist
- Confirm all API credentials for Google Drive, Cohere, Milvus, and OpenAI are set correctly.
- Test the Watch New Files node by adding a PDF and confirm it triggers.
- Verify the Extract from File node extracts text as expected.
- Check embeddings are created and appear in the Milvus collection.
- Test chat questions to confirm relevant answers come back.
Deployment tips
Activate your workflow inside n8n by enabling the Watch New Files trigger node.
For cloud users, n8n runs continuously and listens for new PDFs automatically.
For self-hosted setups, keep the server running steadily; see self-host n8n for hosting ideas.
Use the n8n execution panel to monitor runs and catch errors early.
Adjust node parameters as needed based on logs and usage.
Summary of results
✓ Automates PDF ingestion and vector storage.
✓ Saves hours of manual document processing.
✓ Enables faster, accurate answers from your PDF data.
✓ Supports multiple languages via Cohere “embed-multilingual-v3.0”.
✓ Scales well with large document collections using Milvus.
