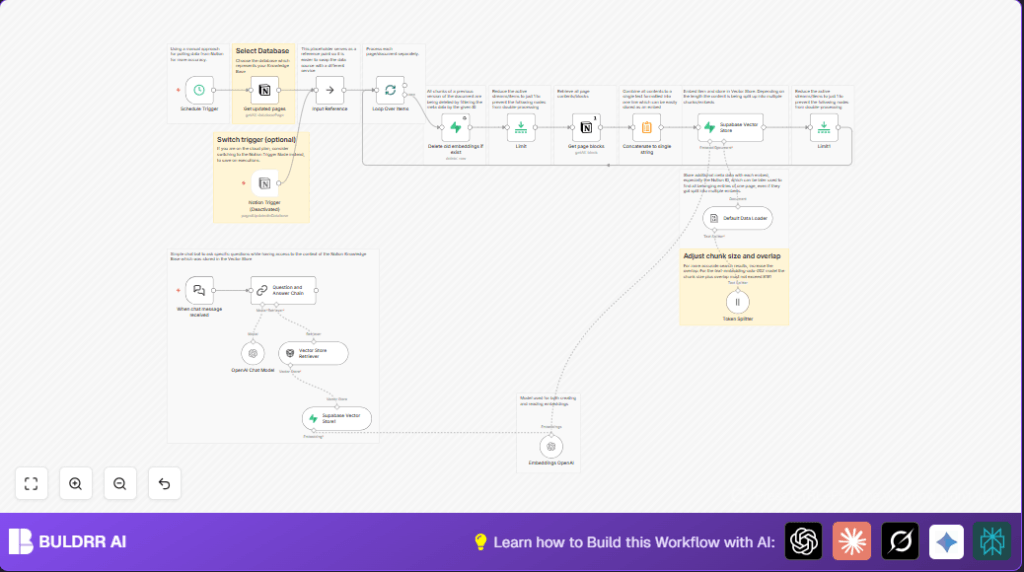
What This Workflow Does
This workflow updates and uses a Notion knowledge base automatically inside n8n. It fixes the problem of long manual search through many pages. The result is fast, accurate answers to questions using OpenAI and Supabase embedding search.
It pulls new or changed Notion pages, removes old saved data, creates new text chunks and embeddings, stores them, and lets users ask questions that get smart answers from the updated data.
Tools and Services Used
- Notion API: To fetch pages and content blocks from the knowledge base.
- OpenAI API: To create embeddings for text and generate chat answers.
- Supabase Vector Store: To save and search text embeddings efficiently.
- n8n: Automation platform to run the workflow steps and connect nodes.
How the Workflow Works: Inputs → Process → Output
Inputs
- Schedule trigger starts the update check on a time interval.
- Notion database ID to fetch updated pages.
- OpenAI API key for embedding and chat model.
- Supabase credentials for embedding storage.
Processing Steps
- Get Notion pages updated in last minute.
- Loop through updated pages one by one.
- Delete old embeddings in Supabase for each updated page.
- Fetch all content blocks of each page from Notion.
- Combine all blocks into one text string.
- Split text into chunks of 500 tokens for efficient embedding.
- Create embeddings for each chunk using OpenAI.
- Save embeddings with page info in Supabase.
- Accept chat questions via webhook node.
- Use vector store retriever to find matching chunks.
- Generate answer using OpenAI chat model with retrieved context.
Output
- Clean, up-to-date vector store with fresh embeddings.
- Instant, relevant answers to user questions from the knowledge base.
Who Should Use This Workflow
This workflow is good for people who want to make their Notion knowledge bases smart and searchable. Users who need fast answers without searching manually will like this.
Anyone who wants to keep the data fresh automatically, without spending hours updating embeddings by hand, will find this useful.
Beginner Step-by-Step: How to Use This Workflow in n8n
Step 1: Download and Import
- Download the workflow file by clicking the Download button on this page.
- Open the n8n editor where you want to run the workflow.
- Use “Import from File” in n8n to load the workflow you downloaded.
Step 2: Add Credentials and IDs
- Add your Notion API credentials under Credentials in n8n.
- Enter your OpenAI API key in the corresponding OpenAI node.
- Add Supabase credentials in the Supabase node and check the table name “documents” exists.
- Update any Notion database IDs or page IDs if needed in the nodes.
Step 3: Test the Workflow
- Run the workflow manually once to see if it fetches pages and creates embeddings.
- Check any errors or missing data to fix the config.
Step 4: Activate for Production Use
- After testing success, activate the workflow in n8n.
- Keep the schedule trigger active to poll for updates automatically.
- Use the chat webhook URL to send questions and receive answers.
For self hosting n8n, see self-host n8n for help running the workflow continuously.
Customizations
- Change token chunk size in the Token Splitter node if you want fewer or smaller pieces of text.
- Select different embedding models in the OpenAI node if cost or accuracy needs vary.
- Turn on the Notion Trigger node instead of Schedule Trigger to listen for updates automatically and save calls.
- Add more metadata fields like author or date in the Supabase node to improve search detail.
Common Problems and Fixes
- No pages found on update check: Check the time filter expression in the Notion getAll node. Make sure pages have been edited recently.
- Embeddings not saved in Supabase: Confirm table name is “documents” and metadata keys are correct.
- Chat webhook unreachable: Ensure the webhook URL is public, workflow is active, and there is no firewall blocking access.
Summary of Benefits and Results
✓ Saves hours of manual knowledge base updates every day.
✓ Keeps vector store embeddings fresh and accurate.
✓ Answers questions instantly using latest Notion content.
✓ Makes knowledge bases smarter with automation.
✓ Easy to use and adapt for your own data and needs.