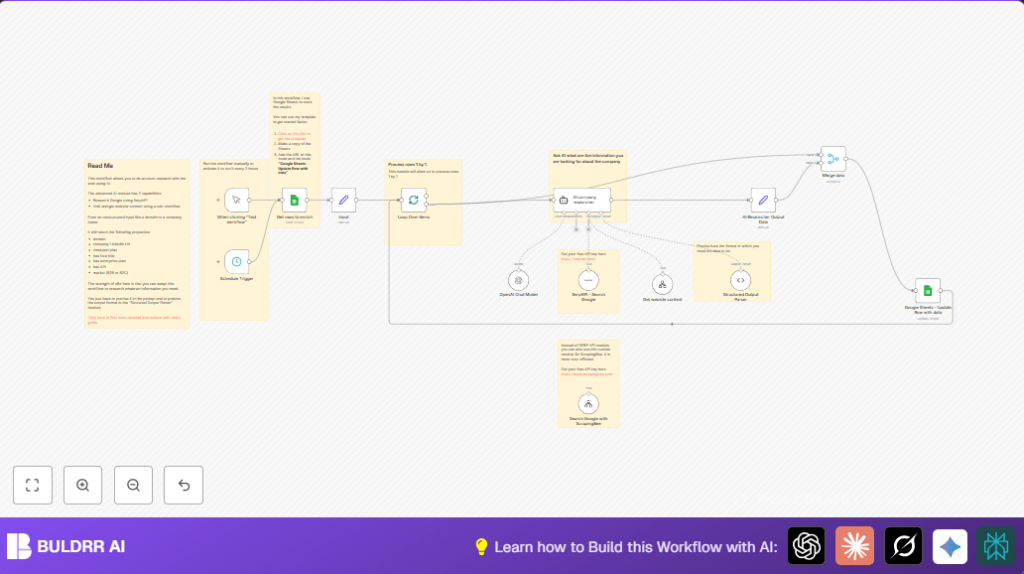
What This Automation Does
This workflow gets company info from a list in Google Sheets and updates that list automatically.
It uses AI to find details like website, LinkedIn, pricing, free trials, and case studies.
This stops wasting time on slow, manual research and adds correct data fast.
You get detailed and fresh company profiles with no typing needed.
The system reads companies one by one from a spreadsheet.
It asks the GPT-4 AI agent to dig up facts about each company with help from Google search data and website content scraping.
Then it checks the AI answer to keep data neat and fills the Google Sheet row automatically, marking each as done.
This runs manually or on a schedule, so your list stays up to date by itself.
Who Should Use This Workflow
This workflow is best for business analysts and marketing teams who need to study many companies.
It suits users who want to save hours weekly by avoiding manual lookups.
If managing company data in Google Sheets and needing extra details like pricing and LinkedIn, this is helpful.
Non-technical users who prefer easy automation without coding can also use it.
Tools and Services Used
- Google Sheets API: Reads and writes company data in spreadsheet.
- OpenAI API (GPT-4): Runs AI agent to research company info.
- SerpAPI or ScrapingBee API: Searches Google results to help AI find pricing and case studies.
- n8n automation platform: Pulls data, calls APIs, processes info, and updates sheets on schedule.
Beginner Step-by-Step: How to Build This in n8n
Step 1: Import Workflow
- Download the workflow file using the Download button on this page.
- Open the n8n editor where you manage automations.
- Click “Import from File” and select the downloaded workflow JSON.
Step 2: Setup Credentials and IDs
- Add your OpenAI API Key in the Credentials section.
- Add your SerpAPI or ScrapingBee API Key similarly.
- Edit Google Sheets nodes to use your spreadsheet’s document ID and sheet name.
Step 3: Customize Prompts and Inputs if Needed
- Check the AI company researcher agent prompt; it contains a clear prompt about what company info to find.
- Adjust any field names or extra info you want included in the prompt.
Step 4: Test Workflow
- Run the workflow manually by clicking “Test Workflow” using the Manual Trigger node.
- Check the Google Sheet updates after the run finishes for correct data.
Step 5: Activate Workflow for Production
- Enable the Schedule Trigger node to run every 2 hours or chosen time.
- Turn the workflow active in n8n to run automatically.
- If using self-host n8n, visit self-host n8n for hosting options.
Inputs → Processing → Outputs
Inputs
- Google Sheet with rows containing company names and empty fields for info.
- API Keys for OpenAI and Google search scraping (SerpAPI or ScrapingBee).
Processing Steps
- Get rows needing company data enrichment from Google Sheets.
- Use SplitInBatches to handle companies one at a time.
- Send company names to OpenAI GPT-4 with a prompt asking for domain, LinkedIn, B2B/B2C, pricing, APIs, trials, and case studies.
- Use SerpAPI or ScrapingBee to pull Google search results about pricing and case studies.
- Extract website content in a sub-workflow to help analyze company details.
- Parse AI response into structured JSON fields.
- Merge enriched data back with original row info.
- Update Google Sheet row with all found company info and mark as “done”.
Outputs
- Google Sheet updated with accurate and fresh company data.
- Rows marked as completed to avoid duplicate work next run.
Customizations ✏️
- Change AI prompt in the AI company researcher to include CEO name, revenue, or more details.
- Switch from SerpAPI to ScrapingBee by replacing the relevant node and updating the API key.
- Modify the Google Sheets filter to enrich only certain companies by market or location.
- Extend AI prompt and sheet columns to capture more integrations or tools.
- Adjust the schedule trigger node timing for how often the workflow runs.
Troubleshooting 🔧
Invalid API key error in OpenAI node
Check the OpenAI API Key in n8n credentials.
Make sure it is current and typed correctly.
Google Sheets update fails with “row not found”
Ensure the row number matches the Google Sheet’s layout.
Try refreshing the node’s schema or recheck filters.
AI researcher returns incomplete or null data
Reduce batch size to avoid API limits.
Clarify prompt, or check usage limits with OpenAI.
Pre-Production Checklist ✅
- Confirm Google Sheets document ID and sheet name are correct in nodes.
- Test connections to OpenAI, SerpAPI, or ScrapingBee in n8n settings.
- Run some test companies manually to check accuracy.
- Validate AI output matches expected JSON structure in the parser.
- Backup Google Sheet data before large updates.
Deployment Guide
After testing, turn the workflow live in n8n.
Set the schedule trigger to your preferred interval.
Watch the execution logs for errors.
Update API keys or prompt if the company list grows bigger.
With self-host n8n, you can run this workflow on your own server anytime.
Summary
✓ Saves hours every week by replacing manual company research.
✓ Automatically gets detailed company info from AI and web data.
✓ Updates Google Sheets with fresh, structured business intelligence.
✓ Runs on schedule or on demand for convenience.
✓ Works well for analysts and marketing teams needing accurate data fast.
