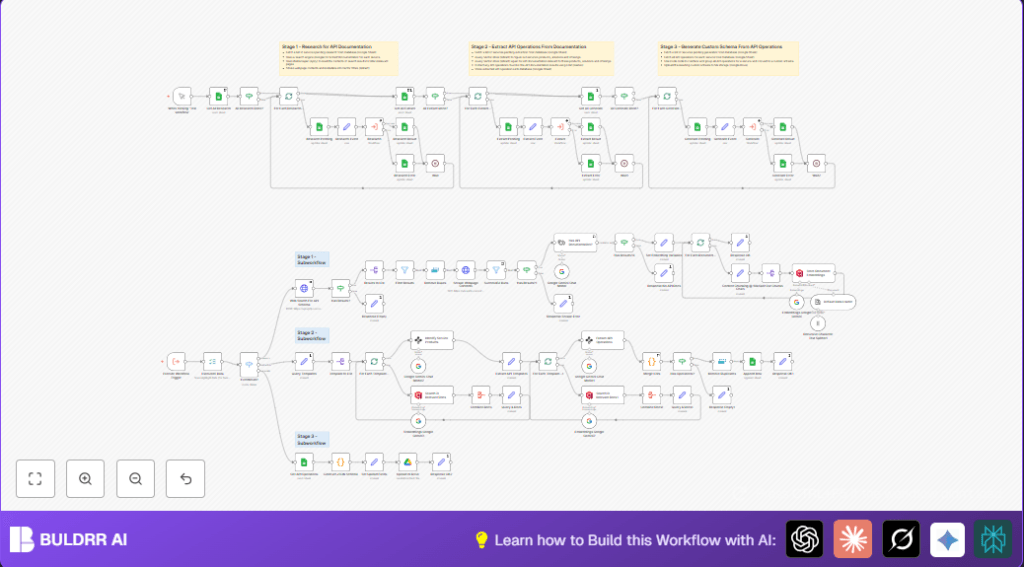
What This Workflow Does
This workflow finds and extracts API information from website pages automatically.
The problem it solves is gathering API data from many scattered web sources is slow and error-prone.
It gives a clear JSON summary and updates Google Sheets and Drive with API details.
You get fast, organized API info that helps build integrations easier and saves hours of manual search.
Tools and Services Used
- n8n Automation Platform: Runs and manages the workflow with nodes.
- Google Sheets API: Stores research services and API extraction data.
- Google Drive API: Uploads the final API JSON schemas.
- Apify API: Performs programmable web searches and scrapes webpage content.
- Qdrant Vector Database: Holds text embeddings for semantic search.
- Google Gemini LLM API: Analyzes text, identifies API documentation, and extracts API operations.
Workflow Inputs, Processing, and Outputs
Inputs
- List of service names and URLs from Google Sheets needing API research.
- Search phrases based on service info to find API doc pages.
Processing Steps
- Do a web search via Apify to find relevant API schema pages.
- Clean and scrape content from found URLs, ignoring images and scripts.
- Convert scraped text to vector embeddings stored in Qdrant for quick searching.
- Use Google Gemini LLM to check if content holds API docs, and extract endpoints, methods, and descriptions.
- Remove duplicate API operations and combine unique ones.
- Save results to Google Sheets, create JSON API schema files, and upload them to Google Drive.
Outputs
- Updated Google Sheets with extracted API operations.
- JSON file per service summarizing all API paths and methods.
- Status flags in Sheets indicating processing progress.
Beginner Step-by-Step: How to Use This Workflow in n8n Production
Step 1: Download and Import
- Download the ready-to-use workflow file from this page.
- Go to your n8n editor.
- Use Import from File option to import the workflow.
Step 2: Configure Credentials and IDs
- Add API Keys for Google Sheets, Google Drive, Apify, Qdrant, and Google Gemini in your n8n credentials section.
- Update any sheet IDs, folder IDs, or email addresses used in the workflow nodes.
- Check for any code nodes or HTTP requests where URL or prompt text needs to be pasted or updated.
Step 3: Test the Workflow
- Run the workflow manually using the Manual Trigger node.
- Watch each step’s output and fix any credential or ID errors that appear.
Step 4: Activate Workflow for Production
- Once tests run smoothly, set the workflow to active.
- You can schedule runs or trigger manually inside n8n UI.
- If self hosting n8n, consider checking self-host n8n tips for stable operation.
How the Workflow Works Inside
The input starts from Google Sheets rows marked as pending API research.
Each service’s name and URL are used to fire Apify’s Google Search, searching for API docs pages but skipping irrelevant types.
Search results are filtered to remove duplicates or low quality URLs.
Clean scraping is done on the filtered URLs to pull visible text content only.
All page contents are converted with Google Gemini embeddings and stored in Qdrant.
The LLM then finds documents that likely hold API endpoints.
It extracts structured API data: method, endpoint, and descriptions.
Duplicates are removed and only unique API operations are kept.
The extracted APIs are logged into Google Sheets for review.
Finally, an aggregated JSON schema file is created and uploaded to Google Drive.
Common Problems and How to Handle Them
- No results in web search: Check search terms used in the Web Search For API Schema node. Loosen filters or fix URL format.
- Empty API operation extraction: Confirm scraping actually got API docs content. Increase scraping depth if needed.
- Google Sheets update fails: Verify sheets ID and credentials with Sheets API enabled.
- Embeddings not stored in Qdrant: Confirm correct collection name, API keys, and network connectivity.
Customizations
- Change search keywords in the Web Search For API Schema node to target different API types or sites.
- Adjust document chunk sizes in text splitter nodes for better embedding.
- Switch Qdrant collection names if managing multiple services.
- Modify JSON schema generation code to create OpenAPI formats or add security details.
- Replace Google Drive uploads with other storage options like S3 if preferred.
Summary of Benefits and Results
→ Saves hours of manual API research.
→ Turns scattered web API docs into easy-to-use JSON schemas.
→ Keeps track of research progress with Google Sheets status updates.
→ Combines AI, vector search, and programmable scraping to improve accuracy.
→ Makes integration projects faster and less error prone.
